SRAM是可在任何CMOS工艺中“免费获得”的存储器。自CMOS诞生以来,SRAM一直是任何新CMOS工艺的开发和生产制造的技术驱动力。利用最新的所谓的“深度学习领域专用域结构”(DSA),每个芯片上的SRAM数量已达到数百兆位。这导致了两个具体挑战。
第一个挑战是使用FinFET晶体管的最新CMOS技术使单元尺寸的效率越来越低。在图1中可以看到这一点,其中SRAM单元大小是CMOS技术节点的函数。
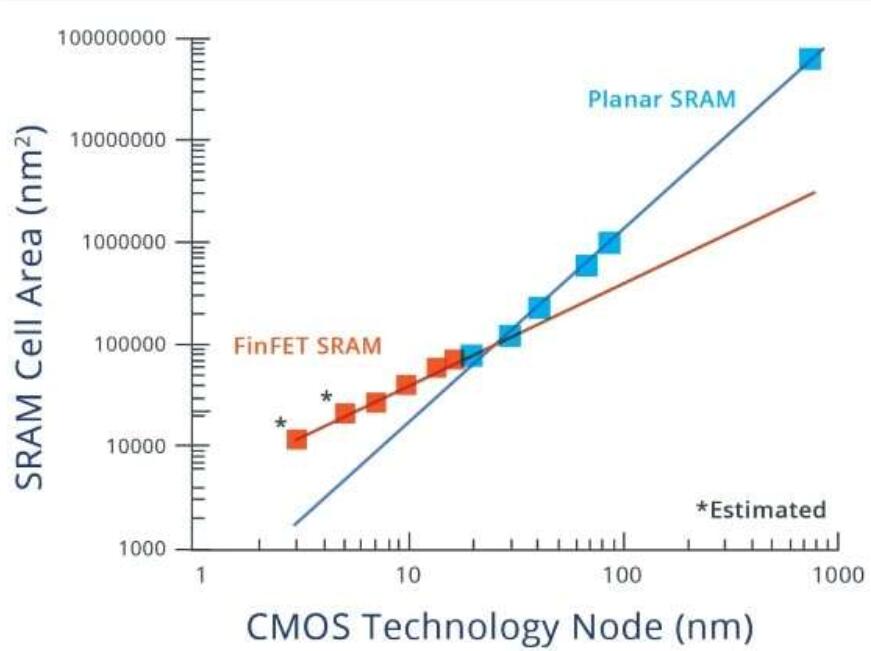
图1:过去30年中6晶体管SRAM单元尺寸的缩小趋势。一旦FinFET晶体管成为CMOS的基础,请注意减速。
平面到FinFET的过渡对SRAM单元的布局效率有重大影响。使用FinFET逐渐缩小关键节距已导致SRAM单元尺寸的迅速减小。鉴于对更大的片上SRAM容量的需求不断增长,这样做的时机不会更糟。离SRAM将主导DSA处理器大小的局面并不遥远。
第二个挑战是从正电源通过SRAM单元流到地面的泄漏电流。这主要是由于亚阈值晶体管泄漏是指数激活的,这意味着随着芯片温度的升高,泄漏急剧增加。由于它没有做任何有用的工作,因此会浪费能源。尽管通常被称为静态功耗,但这种泄漏也会在SRAM处于活动使用状态时发生,并形成能量浪费的下限。
已经采用了近20年的缓解技术来限制这种影响,最先进的技术是将SRAM电源电压从其工作值降低到所谓的数据保持电压(DRV)。最初此技术可将工作电源电压下的漏电流降低5到10倍。随着技术节点的发展,电源电压不断降低,工作电压和DRV之间的净空缩小了,从而导致使用该技术的漏电流降低了约2倍。
既然我们已经基本用尽了所有的泄漏缓解技术,那么越来越大的SRAM容量将导致大量的浪费电流。如图2所示,CPU芯片上的SRAM容量每18个月翻一番。
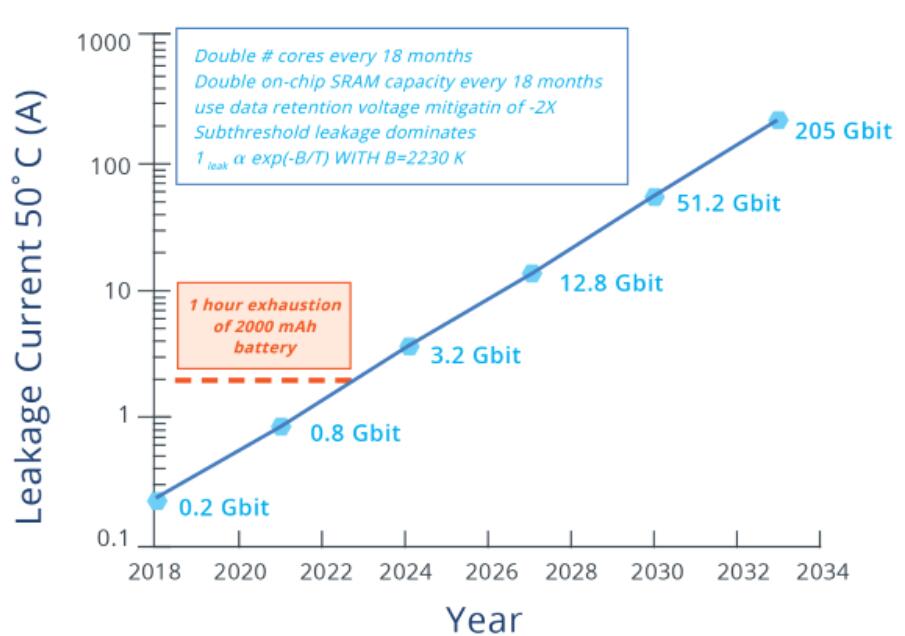
图2:随着片上SRAM容量的不断增加,预计SRAM泄漏电流为50oC。结果是基于低于10nm CMOS的晶体管泄漏数据的仿真。
这两个SRAM挑战与不断提高的片上高速缓存存储速度和容量的需求密不可分,从而带来了成本和能源浪费方面的真正挑战。这种需求来自移动和数据中心应用程序。由于电池寿命的限制,对能源效率的最终要求在前者中是显而易见的,但在后者中也变得至关重要。
由于深度学习而产生的DSA芯片应该可以优化数据中心的性能,成本和能源。作为其一部分,要求它们的芯片将数据“晃动”到正向传播的数据中,该传播已针对针对矩阵/矢量计算进行了优化的处理器进行。将结果数据与“目标”进行比较,然后将“错误数据”“拖拉”回内存以在下一个收敛周期中使用。除了通常需要每秒Tera浮点运算(TFLOPS)的处理器外,还需要越来越快的片上高速缓存来处理这种巨大的数据移动。
在许多此类DSA芯片并行运行的环境中,例如数据中心,此过程的低效率将导致数千安培从主电源流向地面。所有这些浪费的大量泄漏自然会导致巨大的浪费成本。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。
